Training RL agents directly
on real robots

Who am I?
Stable-Baselines

bert

David (aka HASy)
German Aerospace Center (DLR)
Outline
- Why learn directly on real robots?
- Learning from scratch
- Knowledge guided RL
- Questions?
Why learn directly on real robots?
Miki, Takahiro, et al. "Learning robust perceptive locomotion for quadrupedal robots in the wild." Science Robotics (2022)
Rudin, Nikita, et al. "Learning to walk in minutes using massively parallel deep reinforcement learning." CoRL. PMLR, 2022.
Simulation is all you need?

Credits: Nathan Lambert (@natolambert)
Simulation is all you need? (bis)
Simulation is really all you need
Why learn directly on real robots?
- because you can! (software/hardware)
- simulation is safer, faster
- simulation to reality (sim2real): accurate model and randomization needed
- challenges: robot safety, sample efficiency
Learning from scratch
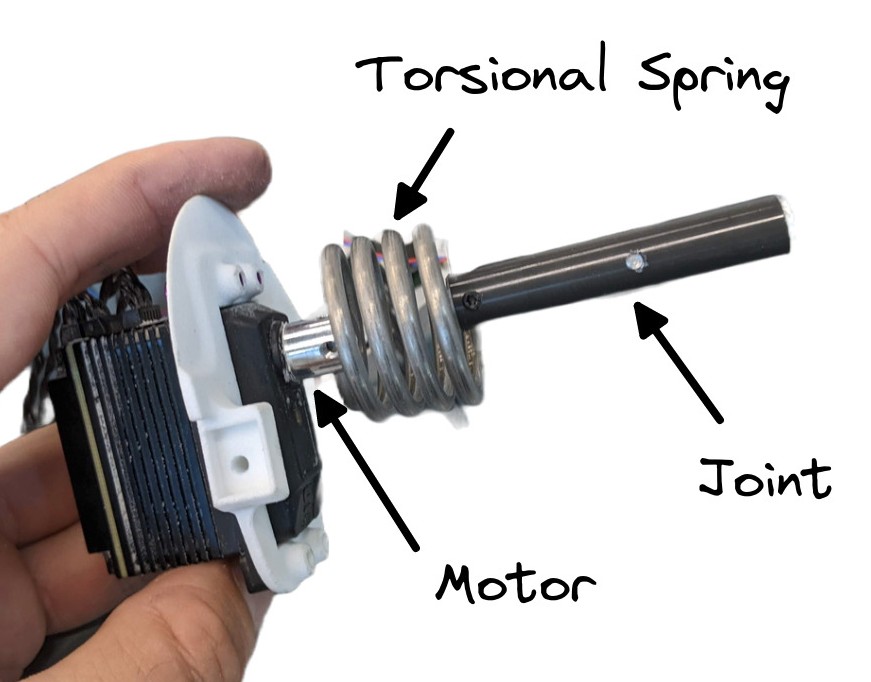
Learning to control an elastic robot
Challenges
- hard to model (silicon neck)
- oscillations
- 2h on the real robot (safety)

Raffin, Antonin, Jens Kober, and Freek Stulp. "Smooth exploration for robotic reinforcement learning." CoRL. PMLR, 2022.
Smooth Exploration for Robotic RL
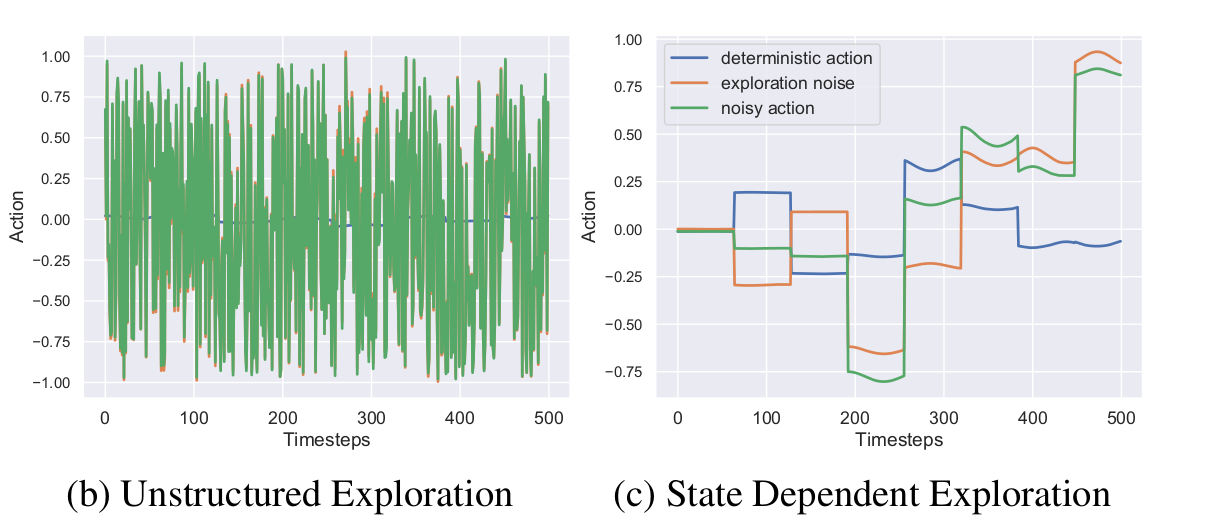
Result
Learning to walk with an elastic quadruped robot
Challenges
- robot safety (5h+ of training)
- manual reset
- communication delay

Raffin, Antonin, Jens Kober, and Freek Stulp. "Smooth exploration for robotic reinforcement learning." CoRL. PMLR, 2022.
DroQ - 20 Minutes Training
Smith, Laura, Ilya Kostrikov, and Sergey Levine. "A Walk in the Park: Learning to Walk in 20 Minutes With Model-Free Reinforcement Learning." arXiv preprint (2022).
Knowledge guided RL
- knowledge about the task (frozen encoder)
- knowledge about the robot (neck)
- RL for improved robustness (CPG + RL)
Learning to drive in minutes / learning to race in hours
Challenges
- minimal number of sensors (image, speed)
- variability of the scene (light, shadows, other cars, ...)
- limited computing power
- communication delay

Raffin, Antonin, Jens Kober, and Freek Stulp. "Smooth exploration for robotic reinforcement learning." CoRL. PMLR, 2022.
Learning a state representation (SRL)
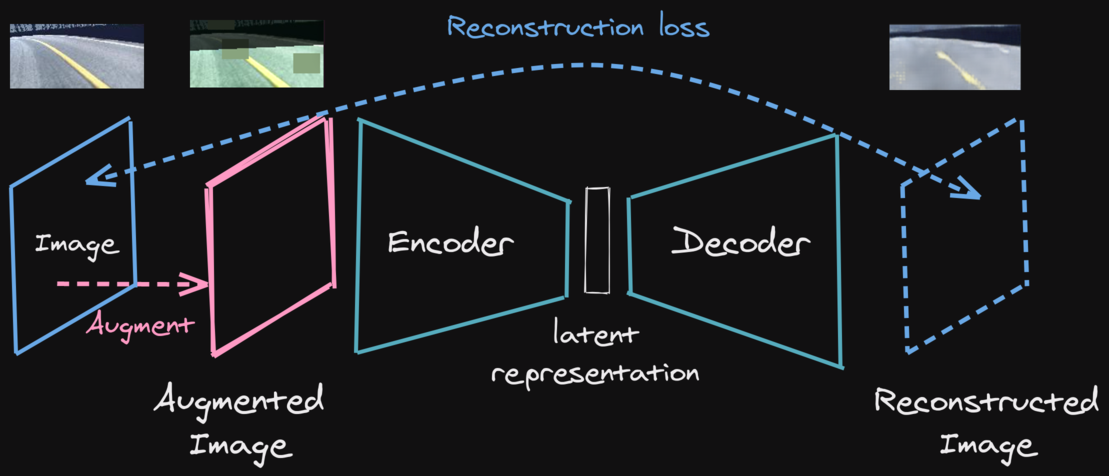
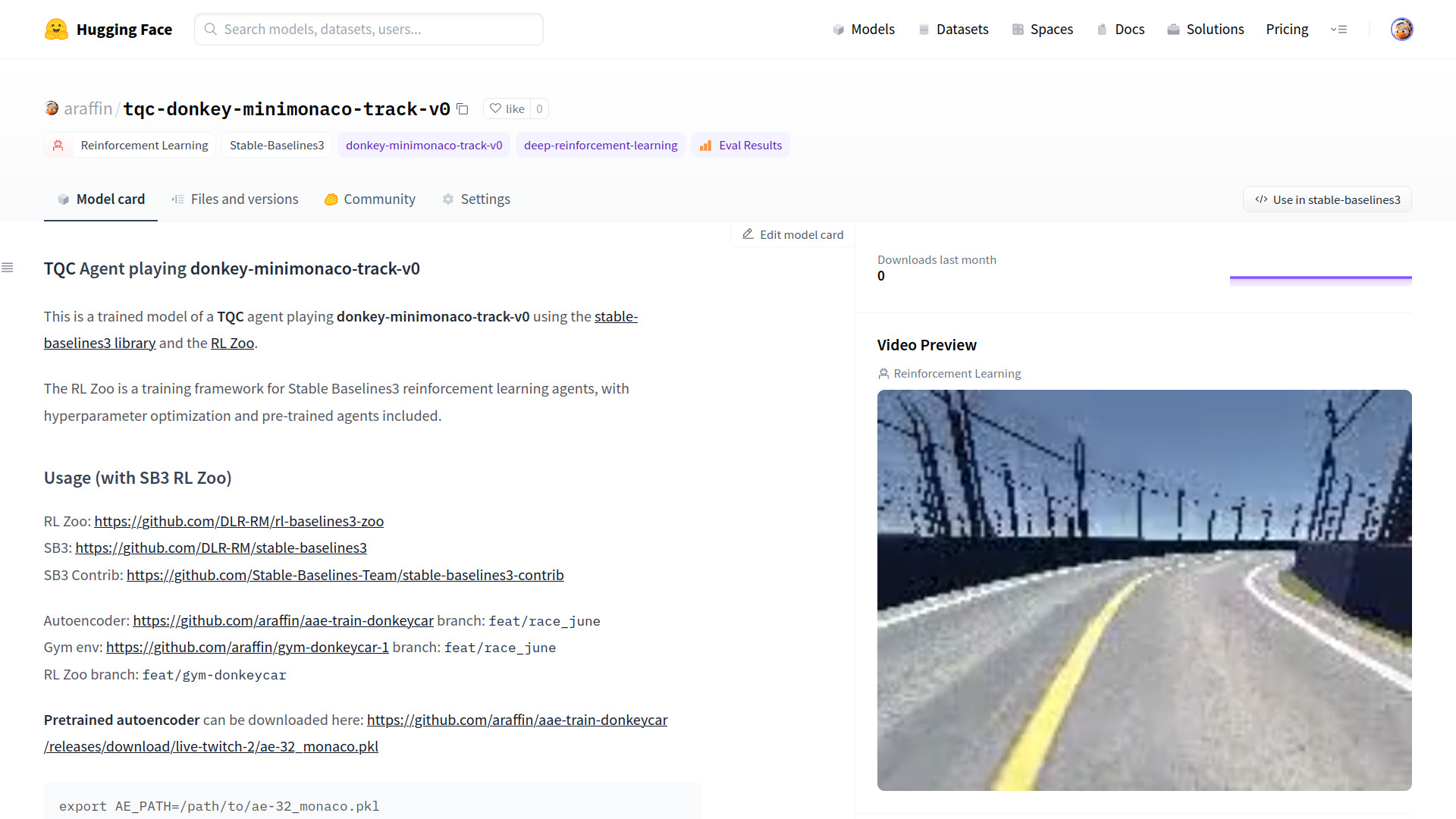
Pre-trained agent on Huggingface hub
Video Serie on YouTube
Learning to Exploit Elastic Actuators for Quadruped Locomotion

Raffin et al. "Learning to Exploit Elastic Actuators for Quadruped Locomotion" In preparation ICRA, 2023.
Otimized CPG + RL
Coupled oscillator

Desired foot position
closing the loop with RL
Fast Trot (~30 minutes training)
Learning to Exploit Elastic Actuators
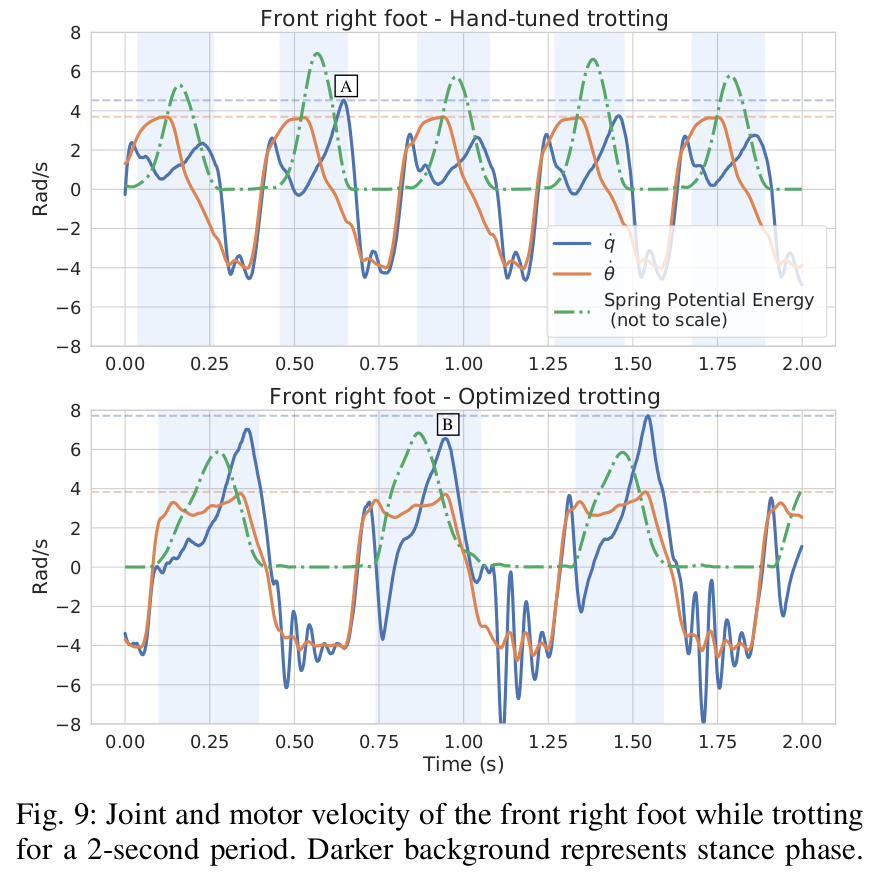

Stabilizing Pronking (1)
Stabilizing Pronking (2)
Stabilizing Pronking (3)
Patterns


Recap
simulation is all you need- learning directly on a real robot is possible
- knowledge guided RL to improve efficiency
Questions?
Additional References
RLVS: RL in practice: tips & tricks
ICRA Tutorial: Tools for Robotic Reinforcement Learning
Backup slides
Continuity Cost
- formulation: \[ r_{continuity} = - (a_t - a_{t - 1})^2 \]
- requires a history wrapper
References: generalized State-Dependent Exploration (gSDE), CAPS