Direct Policy Search
(BBO & PG)

GitHub Repository
Aims
- Learn directly a policy (no intermediate $Q^\pi_\theta(s, a)$)
- Policy from a control perspective
- Policy gradient from a classification perspective
Outline
- From line following to autonomous racing
- Bang-bang and PD controller
- Black-box optimization
- From classification to policy gradient
Line following (2014)
Line following and autonomous racing
Learning to race in minutes
Learning to race in an hour
Differential-Drive Robot

Observation Space

obs_high = np.array(
[
self.off_track_threshold, # lateral error
np.inf, # lateral error derivative
],
dtype=np.float32,
)
self.observation_space = spaces.Box(low=-obs_high, high=obs_high)
# Later: [lateral_error, heading_error, forward_velocity,
# angular_velocity, left_wheel_speed, right_wheel_speed,
# curvature, lookahead_lat_2, lookahead_lat_4, lookahead_lat_6]
Action Space

# Action: [left_wheel_speed, right_wheel_speed]
left_wheel_speed = base_speed + steering
right_wheel_speed = base_speed - steering
# 1-D action → steering ∈ [-1, 1]
self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(1,))
Reward
Stay close to the line while moving forward
# Note: always normalize!
lateral_penalty = -((lateral_error / self.off_track_threshold) ** 2)
alive_bonus = 1.0 # otherwise might try to terminate early
reward = alive_bonus + lateral_penalty + forward_velocity
What can be changed for racing?
Termination conditions?
Move forward and stay on the track
off_track = abs(lateral_error) > self.off_track_threshold
terminated = off_track or going_reverse
truncated = self.step_count >= self.max_episode_steps # timeout
Note: timeout/truncation needs special handling in the algorithm
- From line following to autonomous racing
- Bang-bang and PD controller
- Black-box optimization
- From classification to policy gradient
Bang-Bang Control
if lateral_error > 0:
action = STEER_LEFT
else:
action = STEER_RIGHT
PD Control



PD Controller as Policy
$a_t = \textcolor{#1864ab}{K_p} \textcolor{#a61e4d}{e_t} + \textcolor{#1864ab}{K_d} \textcolor{#a61e4d}{\frac{e_t - e_{t -1}}{\Delta t}}$
$a_t = \begin{bmatrix} \textcolor{#1864ab}{K_p} & \textcolor{#1864ab}{K_d} \end{bmatrix} \cdot \begin{bmatrix} \textcolor{#a61e4d}{e_t} \\ \textcolor{#a61e4d}{\frac{e_t - e_{t -1}}{\Delta t}} \end{bmatrix}$
$a_t = \textcolor{#1864ab}{\theta}^\top \textcolor{#a61e4d}{s_t}$
$\pi_{\textcolor{#1864ab}{\theta}}(\textcolor{#a61e4d}{s_t}) = \textcolor{#1864ab}{\theta}^\top \textcolor{#a61e4d}{s_t}$ a linear policy!
Questions?
- From line following to autonomous racing
- Bang-bang and PD controller
- Black-box optimization
- From classification to policy gradient
How to find a good policy?
$\pi_{\textcolor{#1864ab}{\theta}}(\textcolor{#a61e4d}{s_t}) = \begin{bmatrix} \textcolor{#1864ab}{K_p} & \textcolor{#1864ab}{K_d} \end{bmatrix}^\top \textcolor{#a61e4d}{s_t} = \textcolor{#1864ab}{\theta}^\top \textcolor{#a61e4d}{s_t}$
- how to find $K_p$, $K_d$ automatically?
- how to extend $s_t$?
ex: $s_t = [e_t, \frac{e_t - e_{t -1}}{\Delta t}, v_t, \text{curv}_t \ldots]$ - more complex policy $\pi_\theta$?
Black-Box Optimization
$\theta^* = \text{argmin}_{\theta}{J(\theta)}$
Episodic RL?
Exploration in Parameter Space
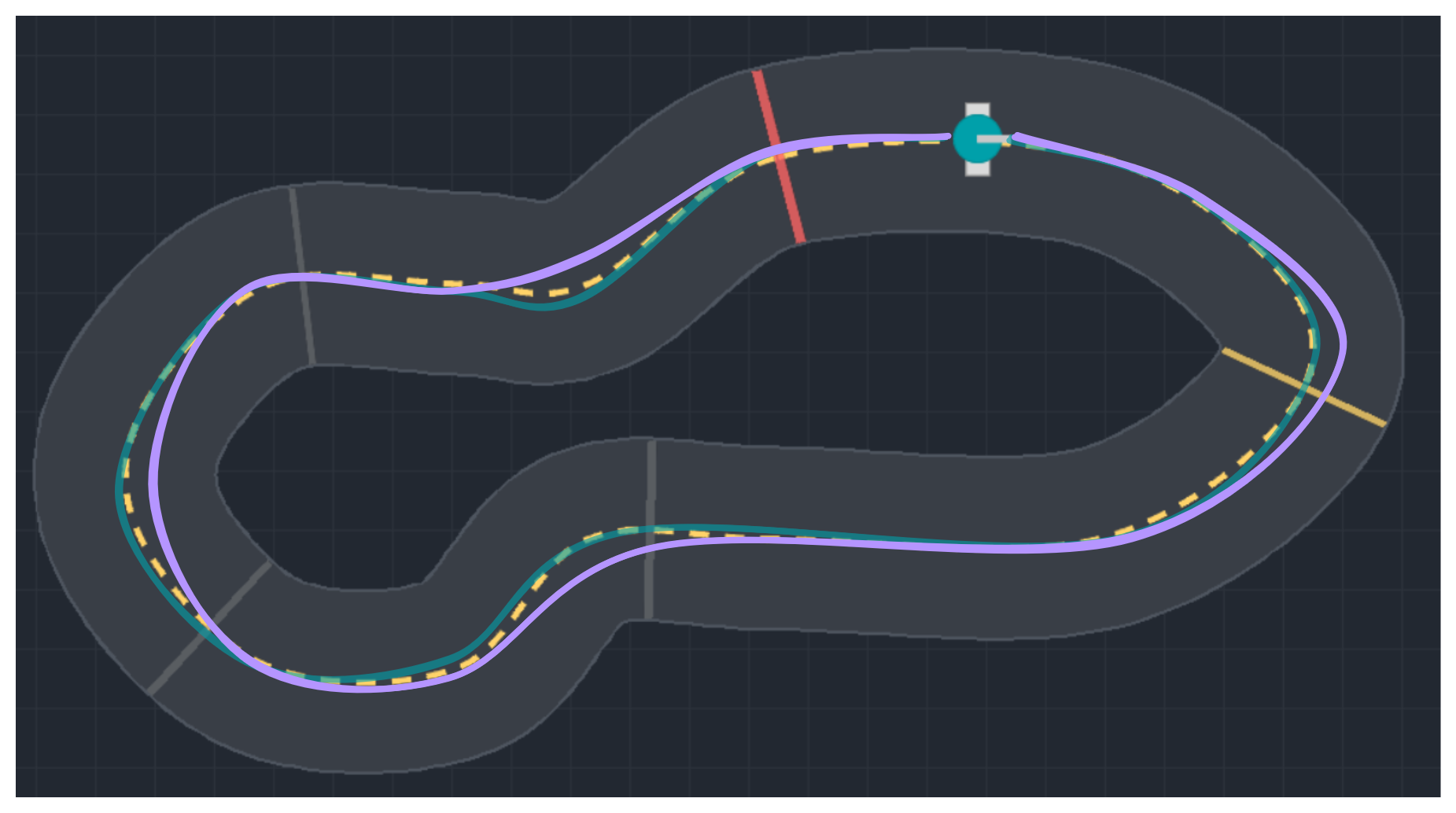
Finding better gains for the PD controller
$\tilde{\theta} = \begin{bmatrix} K_p \\ K_d \end{bmatrix} + \begin{bmatrix} \epsilon_1 \\ \epsilon_2 \end{bmatrix}$
\[ a_t = (\theta + \theta_{\epsilon})^{\top}s_t \]
Learning from human feedback
Raffin, Antonin "Enabling Reinforcement Learning on Real Robots." Diss. TUM, 2024.
Adapting quickly: Retrained from Space
A Simple Evolution Strategy (ES)



Transition: Finite Difference





Mania, Horia, et al. "Simple random search provides a competitive approach to reinforcement learning." NeurIPS 2018
Transition: Finite Difference (2)
Questions?
PD Control and Black Box Optimization (1st notebook)
https://github.com/araffin/rlss26-pg-tutorial- From line following to autonomous racing
- Bang-bang and PD controller
- Black-box optimization
- From classification to policy gradient
BBO Limitations
- Does not use $r_t$, only $R(\tau)$
- Does not scale when $\pi_\theta$ is more complex
- Policy gradient?
Classification 101


Cross-Entropy Loss




RL as classification (1)



Deep Reinforcement Learning: Pong from Pixels - Andrej Karpathy (2016)
RL as classification (2)
- $R$ acts as weight
- $R > 0$ (win -> reinforce the taken action)
- $R < 0$ (lose -> make the taken action less likely)
RL as classification (3)
Discretized version: $\Delta \phi \in \set{-1, -0.5, 0.0, 0.5, 1.0}$
- Ex: taken action is $\Delta \phi = -1.0$ (left)
- Error reduced -> reinforce the taken action
- Error increased -> make the taken action less likely
Policy Gradient Loss (reminder)




Episodic Policy Gradient
(in practice)



Policy Gradient (full)


Some remarks
- Noisy gradient
- Scales with action/policy dim
- Not a true gradient for the discounted case
Nota, Chris, and Philip S. Thomas. "Is the policy gradient a gradient?." 2019.
Tosatto, Samuele, et al. "A temporal-difference approach to policy gradient estimation." ICML, 2022.
PG Training Loop

Exploration in Action Space
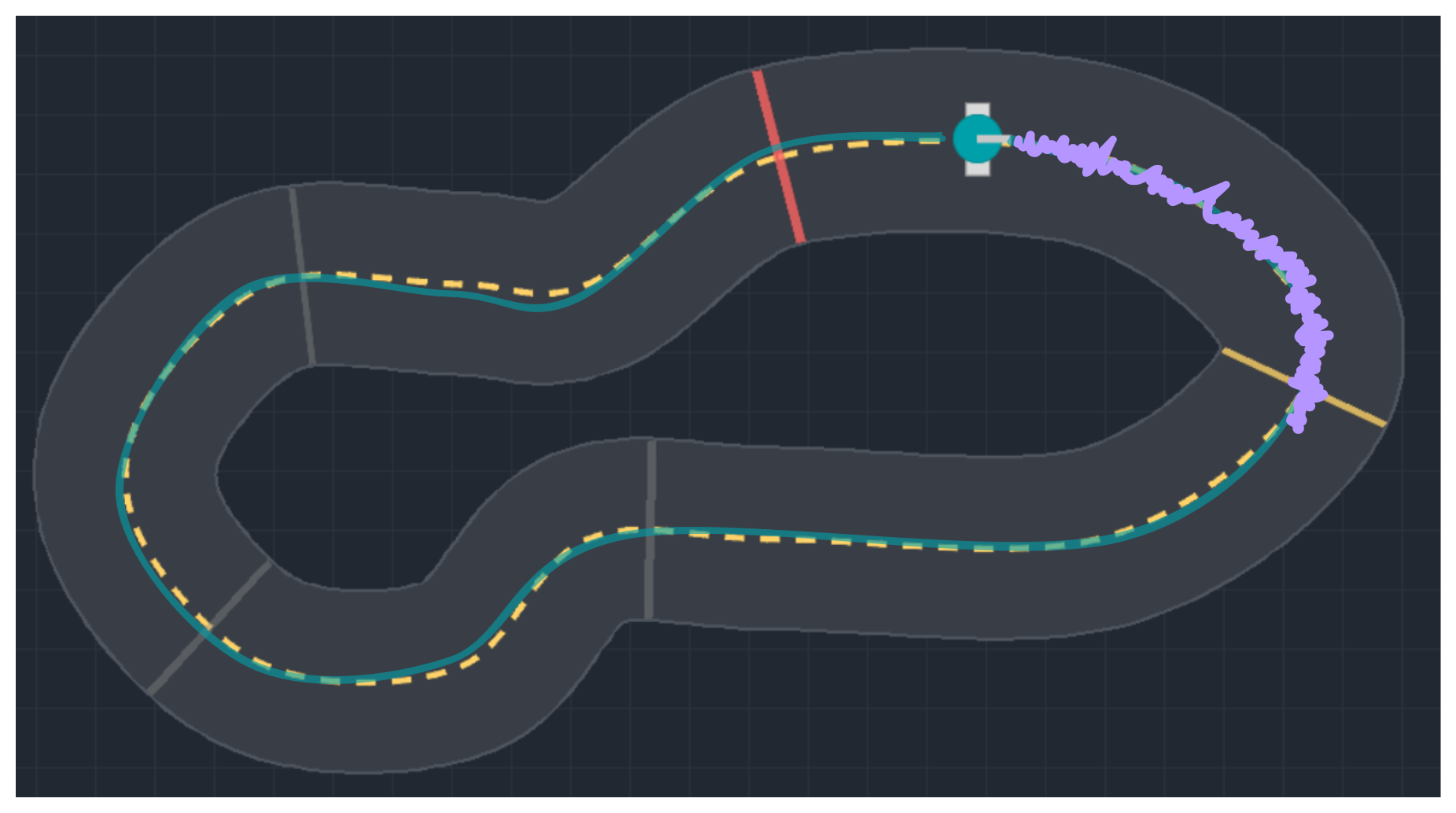
$a_t \sim \pi_\theta(a_t | s_t)$ stochastic policy
Action Distributions: Categorical
$$\pi_\theta(a_i \mid s_t) = \frac{\exp(z_{a_i})}{\sum_{j} \exp(z_{a_{j}})} $$ $$\text{where} \quad z = \theta^\top s_t \quad \text{(logits)}$$
Action Distributions: Gaussian

$\mu_\theta(s_t) = \theta^\top s_t, \ \sigma \ \text{(learnable param)}$
$$\pi_\theta(a_t \mid s_t) = \mathcal{N}(\mu_\theta(s_t), \sigma^2 I)$$