Stable-Baselines3 (SB3) Tutorial
Getting Started With Reinforcement Learning
RL 101



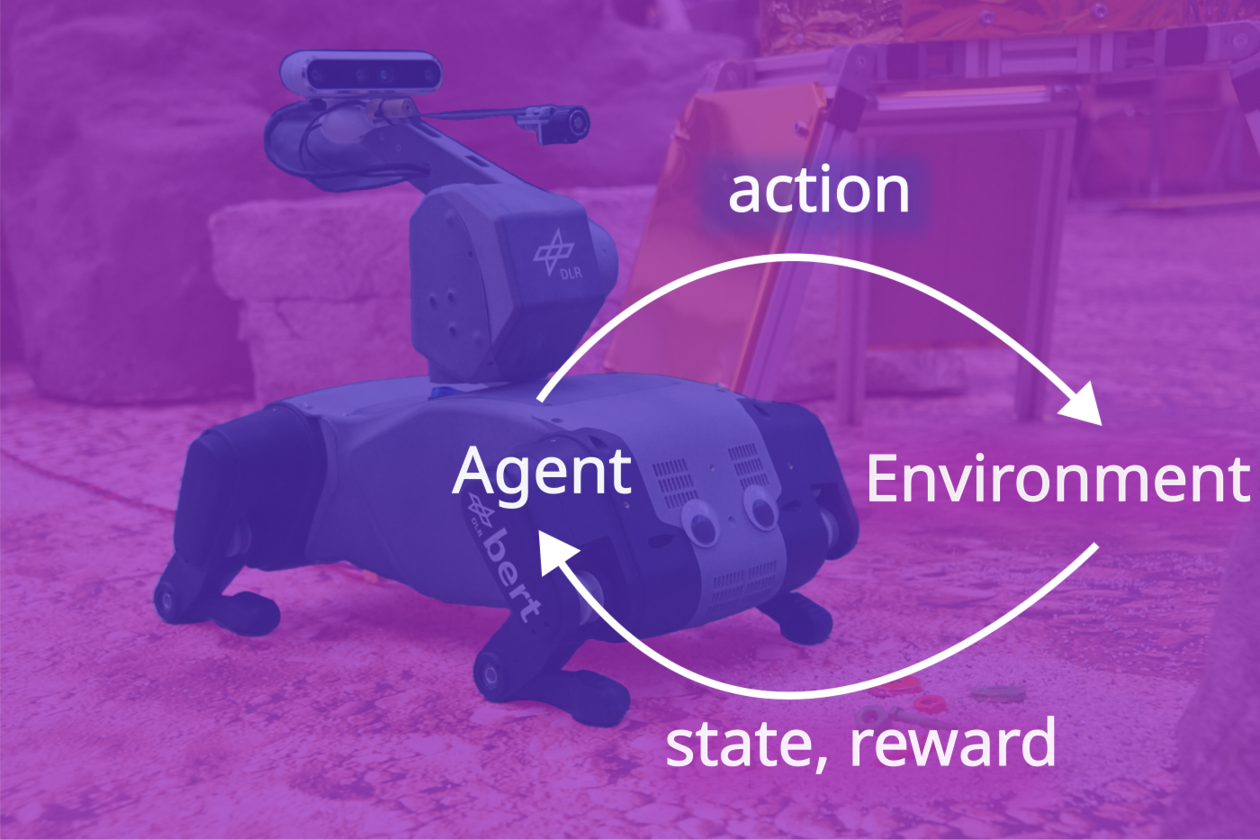
Motivation
Adapting quickly: Retrained from Space
Learning to race in minutes
Learning to control an elastic neck
Outline
- Getting started with Gymnasium
- How to define a custom RL task?
- Getting started with SB3
What is Gymnasium? (1/2)
An Interface
import gymnasium as gym
# Create the environment
env = gym.make("CartPole-v1", render_mode="human")
# Reset env and get first observation
obs, _ = env.reset()
# Step in the env with random actions
for _ in range(100):
action = env.action_space.sample()
# Retrieve new observation, reward, terminations signals
# and additional infos
obs, reward, terminated, truncated, info = env.step(action)
# End of an episode
if terminated or truncated:
obs, _ = env.reset()
Live Demo
What is Gymnasium? (2/2)
A collection of environments

- Getting started with Gymnasium
- How to define a custom RL task?
- Getting started with SB3
RL in Practice: Tips and Tricks
Full video: RL in practice YT playlist
Today: only about how to define custom task
Defining a custom task
- observation space
- action space
- reward function
- termination conditions
RL 102


Choosing the observation space
- start simple
- enough information to solve the task
- do not break Markov assumption
- normalize!
CartPole Observation Space

high = np.array(
[
self.x_threshold * 2,
np.inf,
self.theta_threshold_radians * 2,
np.inf,
],
dtype=np.float32,
)
self.observation_space = gym.spaces.Box(low=-high, high=high, dtype=np.float32)
Choosing the Action space
- start simple
- discrete / continuous
- complexity vs final performance
CartPole Action Space
"""
Actions:
Type: Discrete(2)
Num Action
0 Push cart to the left
1 Push cart to the right
"""
self.action_space = gym.spaces.Discrete(2)
Choosing the reward function
- start simple
- reward shaping
- primary / secondary reward
- normalize!
CartPole Reward
if not terminated:
reward = 1.0
Termination conditions?
- early stopping
- special treatment needed for timeouts
- should not change the task (reward hacking)
CartPole Termination
terminated = bool(
x < -self.x_threshold
or x > self.x_threshold
or theta < -self.theta_threshold_radians
or theta > self.theta_threshold_radians
)
# in the registration:
register(
id="CartPole-v1",
entry_point="gymnasium.envs.classic_control.cartpole:CartPoleEnv",
max_episode_steps=500, # truncation
reward_threshold=475.0,
)
Questions?
- Getting started with Gymnasium
- How to define a custom RL task?
- Getting started with SB3
RL is Hard (Episode #4352)
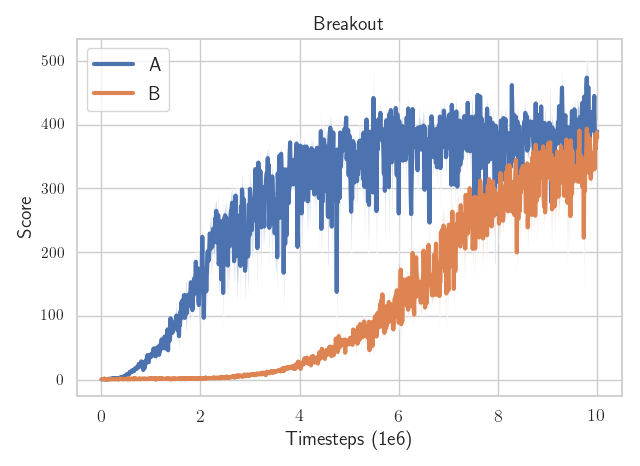
Which algorithm is better?
The only difference: the epsilon value to avoid division by zero in the optimizer
(one is eps=1e-7
the other eps=1e-5)
RL is Hard (Episode #5623)

There is only one line of code that is different.
Stable-Baselines3 (SB3)

https://github.com/DLR-RM/stable-baselines3
Raffin, Antonin, et al. "Stable-baselines3: Reliable reinforcement learning implementations." JMLR (2021)
Reliable Implementations?

- Performance checked
- Software best practices (96% code coverage, type checked, ...)
- Active community (11k+ stars, 3700+ citations, 12M+ downloads)
- Fully documented
Getting Started with SB3
import gymnasium as gym
from stable_baselines3 import SAC
# Train an agent using Soft Actor-Critic on Pendulum-v1
env = gym.make("Pendulum-v1")
model = SAC("MlpPolicy", env, verbose=1)
# Train the model
model.learn(total_timesteps=20_000)
# Save the model
model.save("sac_pendulum")
# Load the trained model
model = SAC.load("sac_pendulum")
# Start a new episode
obs, _ = env.reset()
# What action to take in state `obs`?
action, _ = model.predict(obs, deterministic=True)
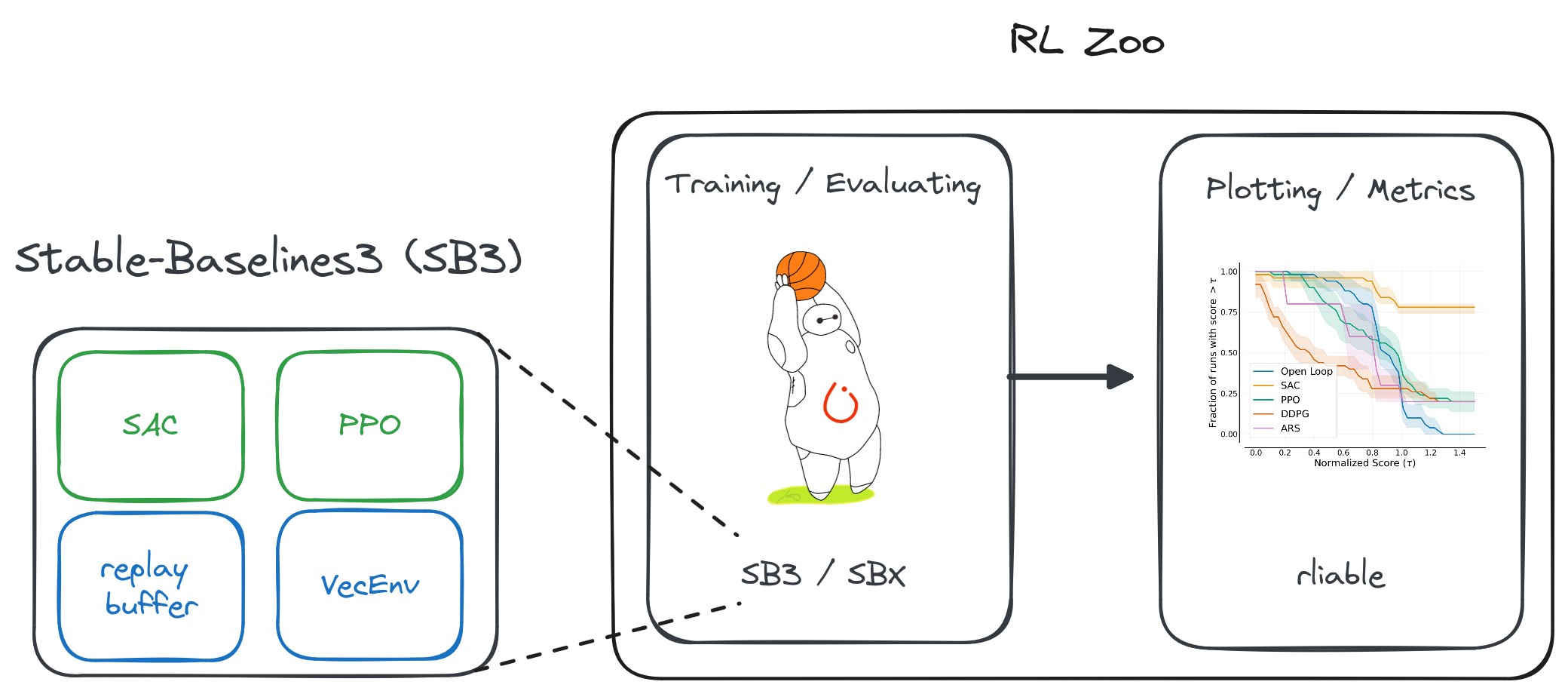
Reproducible Reliable RL: SB3 + RL Zoo
SBX: A Faster Version of SB3
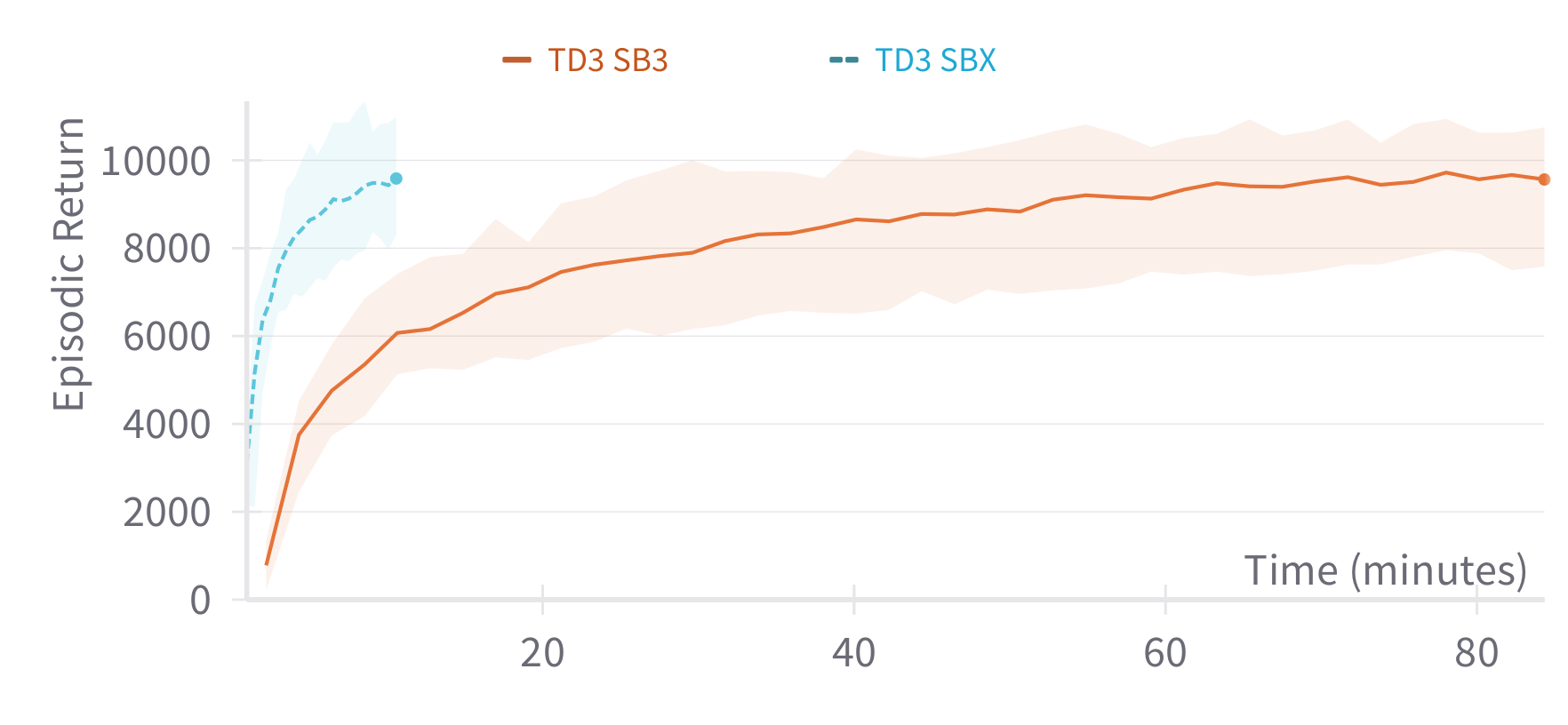
Stable-Baselines3 (PyTorch) vs SBX (Jax)
More gradient steps to improve sample efficiency
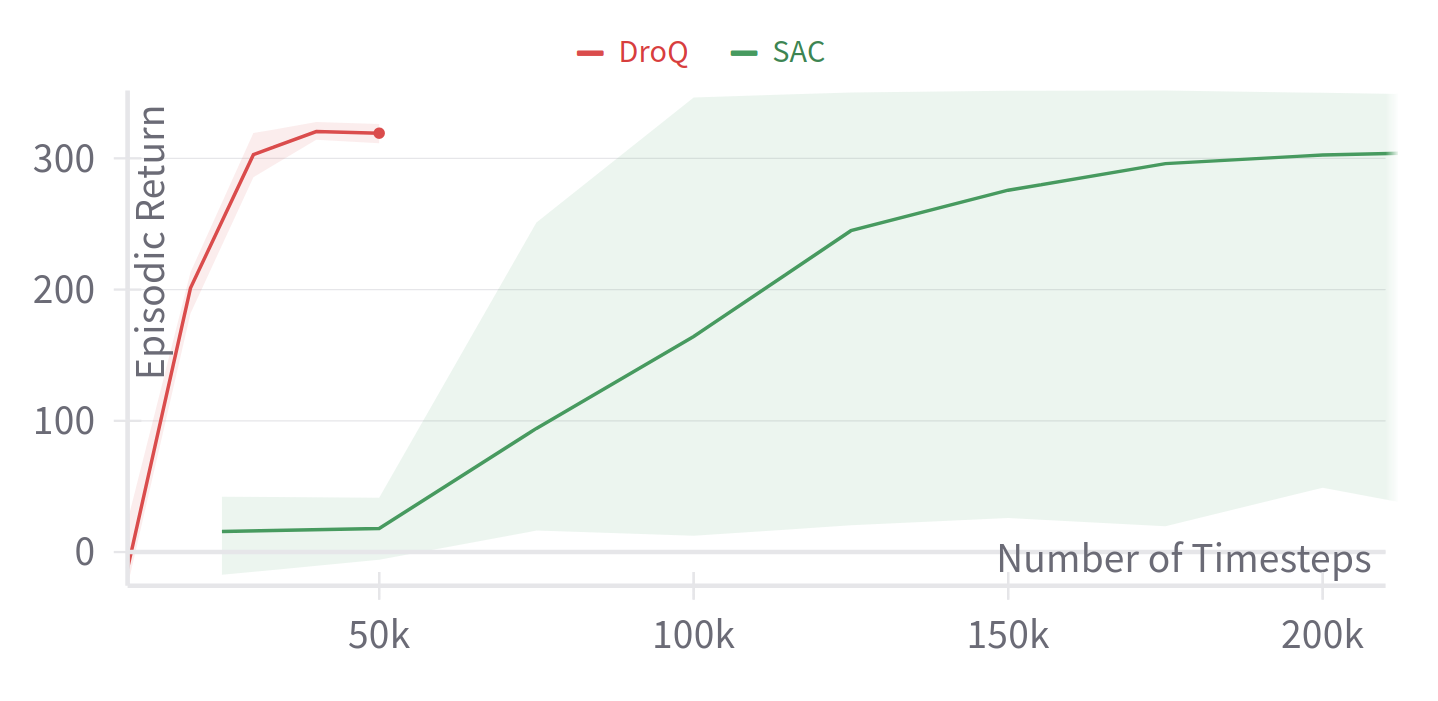
RL from scratch in 10 minutes
Using SB3 + Jax = SBX: https://github.com/araffin/sbx
Recap

Questions?
Colab Notebook
Backup Slides
RL Zoo: Reproducible Experiments
- Training, loading, plotting, hyperparameter optimization
- Everything that is needed to reproduce the experiment is logged
- 200+ trained models with tuned hyperparameters

Plotting
python -m rl_zoo3.cli all_plots -a sac -e HalfCheetah Ant -f logs/ -o sac_results
python -m rl_zoo3.cli plot_from_file -i sac_results.pkl -latex -l SAC --rliable

RL Zoo: Reproducible Experiments
- Training, loading, plotting, hyperparameter optimization
- W&B integration
- 200+ trained models with tuned hyperparameters
In practice
# Train an SAC agent on Pendulum using tuned hyperparameters,
# evaluate the agent every 1k steps and save a checkpoint every 10k steps
# Pass custom hyperparams to the algo/env
python -m rl_zoo3.train --algo sac --env Pendulum-v1 --eval-freq 1000 \
--save-freq 10000 -params train_freq:2 --env-kwargs g:9.8
sac/
└── Pendulum-v1_1 # One folder per experiment
├── 0.monitor.csv # episodic return
├── best_model.zip # best model according to evaluation
├── evaluations.npz # evaluation results
├── Pendulum-v1
│ ├── args.yml # custom cli arguments
│ ├── config.yml # hyperparameters
│ └── vecnormalize.pkl # normalization
├── Pendulum-v1.zip # final model
└── rl_model_10000_steps.zip # checkpoint
Learning to race in an hour
Hyperparameters Study - Learning To Race

Combining Open-Loop Oscillators and RL
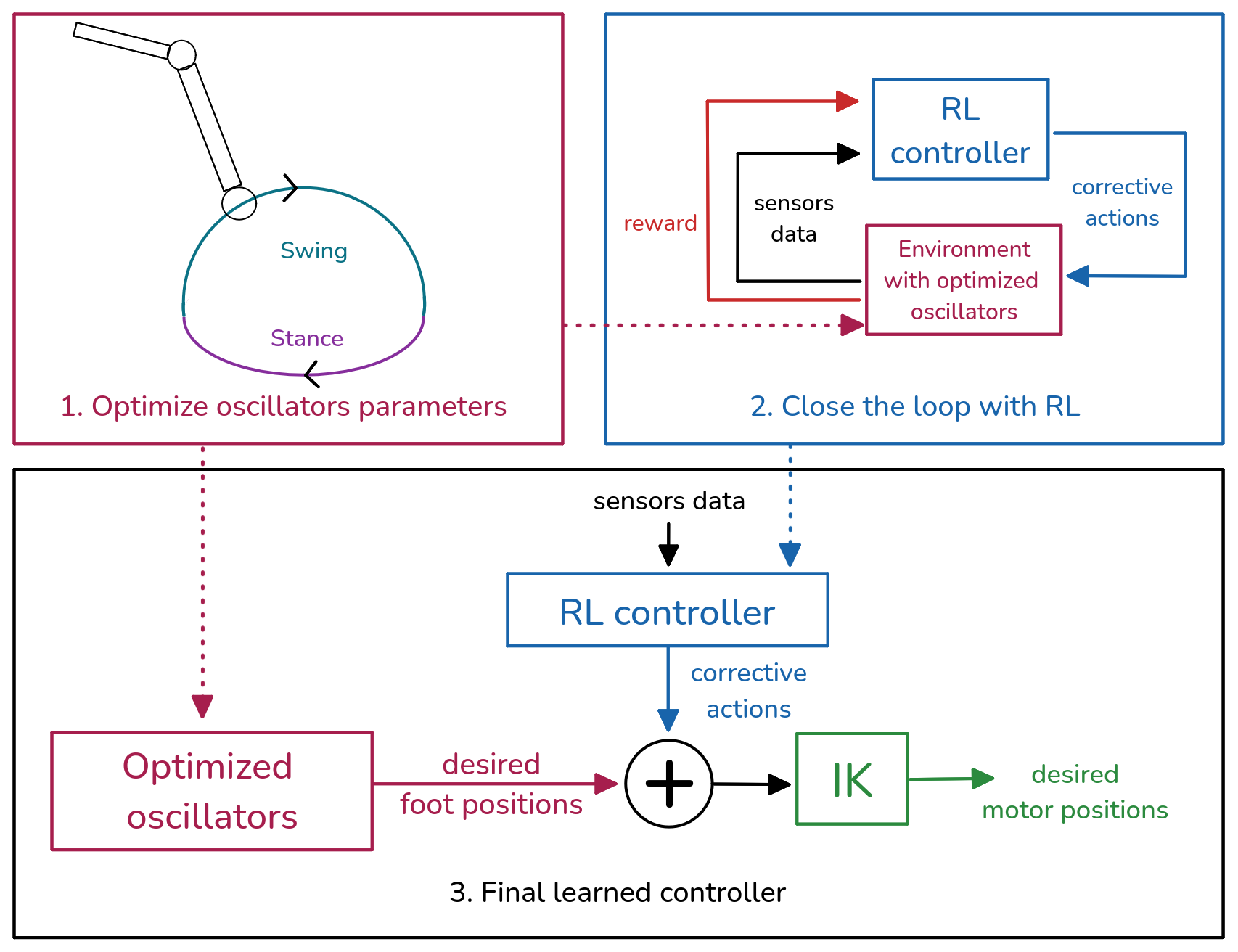
Learning to Exploit Elastic Actuators
RL from scratch
0.14 m/s
Open-Loop Oscillators Hand-Tuned
0.16 m/s
Raffin et al. "Learning to Exploit Elastic Actuators for Quadruped Locomotion" 2023.
Learning to Exploit Elastic Actuators (2)
Open-Loop Oscillators Hand-Tuned
0.16 m/s
Open-Loop Oscillators Hand-Tuned + RL
0.19 m/s
Raffin et al. "Learning to Exploit Elastic Actuators for Quadruped Locomotion" 2023.
Learning to Exploit Elastic Actuators (2)
Open-Loop Oscillators Optimized
0.26 m/s
Open-Loop Oscillators Optimized + RL
0.34 m/s
Raffin et al. "Learning to Exploit Elastic Actuators for Quadruped Locomotion" 2023.