Enabling Reinforcement Learning
on Real Robots

RL 101




Motivation
Learning directly on real robots
Simulation to reality



Rudin, Nikita, et al. "Learning to walk in minutes using massively parallel deep reinforcement learning." CoRL, 2021.
Credit: ANYbotics
Adapting quickly: Retrained from Space
Adapting quickly: different dynamics

Before (3kg)
After, with the 1kg arm
Turning without a hip joint
Turning without a hip joint with new dynamics
Outdoor
Retrained from space (extended)
Cavern Exploration
Challenges of real robot training
- (Exploration-induced) wear and tear
- Sample efficiency
➜ one robot, manual resets - Real-time constraints
➜ no pause, no acceleration, multi-day training - Computational resource constraints
Contributions


Outline
- Reliable Software Tools for RL
- Smooth Exploration for Robotic RL
- Combining Pose Estimation/Oscillators and RL
RL is Hard (Episode #4352)
Which algorithm is better?
The only difference: the epsilon value to avoid division by zero in the optimizer
(one is eps=1e-7
the other eps=1e-5)
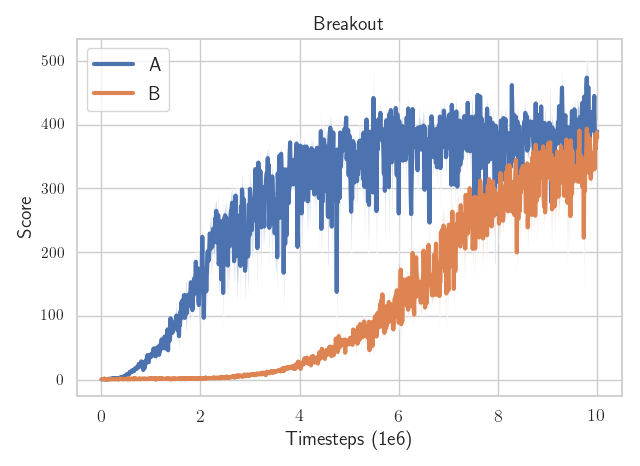
RL is Hard (Episode #5623)

There is only one line of code that is different.
Stable-Baselines3 (SB3)

https://github.com/DLR-RM/stable-baselines3
Raffin, Antonin, et al. "Stable-baselines3: Reliable reinforcement learning implementations." JMLR (2021)
Reliable Implementations?

- Performance checked
- Software best practices (96% code coverage, type checked, ...)
- Active community (11k+ stars, 3700+ citations, 12M+ downloads)
- Fully documented
Reproducible Reliable RL: SB3 + RL Zoo

SBX: A Faster Version of SB3

Stable-Baselines3 (PyTorch) vs SBX (Jax)
More gradient steps to improve sample efficiency

RL from scratch in 10 minutes
Using SB3 + Jax = SBX: https://github.com/araffin/sbx
- Reliable Software Tools for RL
- Smooth Exploration for Robotic RL
- Combining Pose Estimation/Oscillators and RL
generalized State-Dependent Exploration
 Independent Gaussian noise:
\[ \epsilon_t \sim \mathcal{N}(0, \sigma) \]
\[ a_t = \mu(s_t; \theta_{\mu}) + \epsilon_t \]
Independent Gaussian noise:
\[ \epsilon_t \sim \mathcal{N}(0, \sigma) \]
\[ a_t = \mu(s_t; \theta_{\mu}) + \epsilon_t \]
 gSDE:
\[ \theta_{\epsilon} \sim \mathcal{N}(0, \sigma_{\epsilon}) \]
\[ a_t = \mu(s_t; \theta_{\mu}) + \epsilon(z_t; \theta_{\epsilon}) \]
gSDE:
\[ \theta_{\epsilon} \sim \mathcal{N}(0, \sigma_{\epsilon}) \]
\[ a_t = \mu(s_t; \theta_{\mu}) + \epsilon(z_t; \theta_{\epsilon}) \]
Antonin Raffin, Jens Kober & Freek Stulp. "Smooth exploration for robotic reinforcement learning." CoRL, 2022.
Trade-off between
return and continuity cost

Results
- Reliable Software Tools for RL
- Smooth Exploration for Robotic RL
- Combining Pose Estimation/Oscillators and RL
An Open-Loop Baseline for RL Locomotion Tasks
Periodic Policy

Raffin et al. "An Open-Loop Baseline for Reinforcement Learning Locomotion Tasks", RLJ 2024.
Outstanding Paper Award on Empirical Resourcefulness in RL
Cost of generality vs prior knowledge
Combining Open-Loop Oscillators and RL

Learning to Exploit Elastic Actuators
RL from scratch
0.14 m/s
Open-Loop Oscillators Hand-Tuned
0.16 m/s
Raffin et al. "Learning to Exploit Elastic Actuators for Quadruped Locomotion" 2023.
Learning to Exploit Elastic Actuators (2)
Open-Loop Oscillators Hand-Tuned
0.16 m/s
Open-Loop Oscillators Hand-Tuned + RL
0.19 m/s
Raffin et al. "Learning to Exploit Elastic Actuators for Quadruped Locomotion" 2023.
Learning to Exploit Elastic Actuators (2)
Open-Loop Oscillators Optimized
0.26 m/s
Open-Loop Oscillators Optimized + RL
0.34 m/s
Raffin et al. "Learning to Exploit Elastic Actuators for Quadruped Locomotion" 2023.
Feedforward controller
from pose estimation


Integrating Pose Estimation and RL

Neck Control Results

Challenges of real robot training (2)
-
(Exploration-induced) wear and tear
➜ smooth exploration, feedforward controller, open-loop oscillators -
Sample efficiency
➜ prior knowledge, sample-efficient algorithms (DroQ in SBX) -
Real-time constraints
➜ fast implementations, reproducible experiments -
Computational resource constraints
➜ open-loop oscillators, export SB3 policies (ONNX)
Conclusion
- High quality RL software
- Safer exploration
- Leverage prior knowledge
- Future: pre-train in sim, fine-tune on real hardware?
Questions?
Backup Slides
Learning from human feedback
Simulation to reality (2)
...in reality.

Duclusaud, Marc, et al. "Extended Friction Models for the Physics Simulation of Servo Actuators." (2024)
Additional Video
2nd Mission
Before

After, new arm position + magnet
Broken leg
Elastic Neck
Antonin Raffin, Jens Kober, and Freek Stulp. "Smooth exploration for robotic reinforcement learning." CoRL. PMLR, 2022.
Fault-tolerant Pose Estimation

Raffin, Antonin, Bastian Deutschmann, and Freek Stulp. "Fault-tolerant six-DoF pose estimation for tendon-driven continuum mechanisms." Frontiers in Robotics and AI, 2021.
Method
Pose Prediction Results
Pose Estimation Results


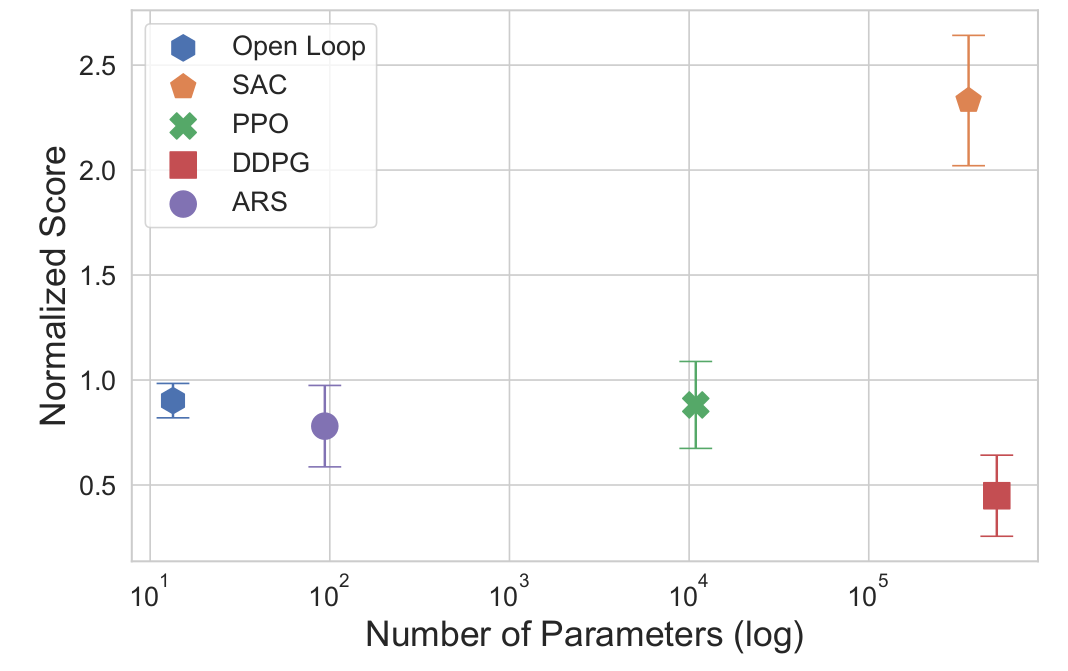
Simulation is all you need?
Parameter efficiency?
RL Zoo: Reproducible Experiments
- Training, loading, plotting, hyperparameter optimization
- Everything that is needed to reproduce the experiment is logged
- 200+ trained models with tuned hyperparameters

Plotting
python -m rl_zoo3.cli all_plots -a sac -e HalfCheetah Ant -f logs/ -o sac_results
python -m rl_zoo3.cli plot_from_file -i sac_results.pkl -latex -l SAC --rliable

RL Zoo: Reproducible Experiments
- Training, loading, plotting, hyperparameter optimization
- W&B integration
- 200+ trained models with tuned hyperparameters
In practice
# Train an SAC agent on Pendulum using tuned hyperparameters,
# evaluate the agent every 1k steps and save a checkpoint every 10k steps
# Pass custom hyperparams to the algo/env
python -m rl_zoo3.train --algo sac --env Pendulum-v1 --eval-freq 1000 \
--save-freq 10000 -params train_freq:2 --env-kwargs g:9.8
sac/
└── Pendulum-v1_1 # One folder per experiment
├── 0.monitor.csv # episodic return
├── best_model.zip # best model according to evaluation
├── evaluations.npz # evaluation results
├── Pendulum-v1
│ ├── args.yml # custom cli arguments
│ ├── config.yml # hyperparameters
│ └── vecnormalize.pkl # normalization
├── Pendulum-v1.zip # final model
└── rl_model_10000_steps.zip # checkpoint
Learning to race in an hour
Hyperparameters Study - Learning To Race
